
(来源:华安基金)
听,这是这个时代最昂贵的声音。
这不是华尔街的敲钟声,也不是印钞机的轰鸣声,而是数百万台服务器风扇转动的风切声,是冷却液在管路里奔涌的水流声,是电流击穿变压器的嗡鸣声。
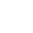
过去两年,我们目睹了一场人类历史上罕见的“点科技树”运动——英伟达的市值突破了4万亿美元,黄仁勋那件黑色皮衣成了硅谷的代表,而所有人的目光都聚焦在那个硬币大小的硅片上——GPU(显卡)。大家迷信地认为,只要堆叠足够多的显卡,只要拥有足够多的GB200或者B300,那个全知全能的“硅基终极”就会在某一个时刻苏醒。
但是,真相往往隐藏在聚光灯照射不到的阴影里。
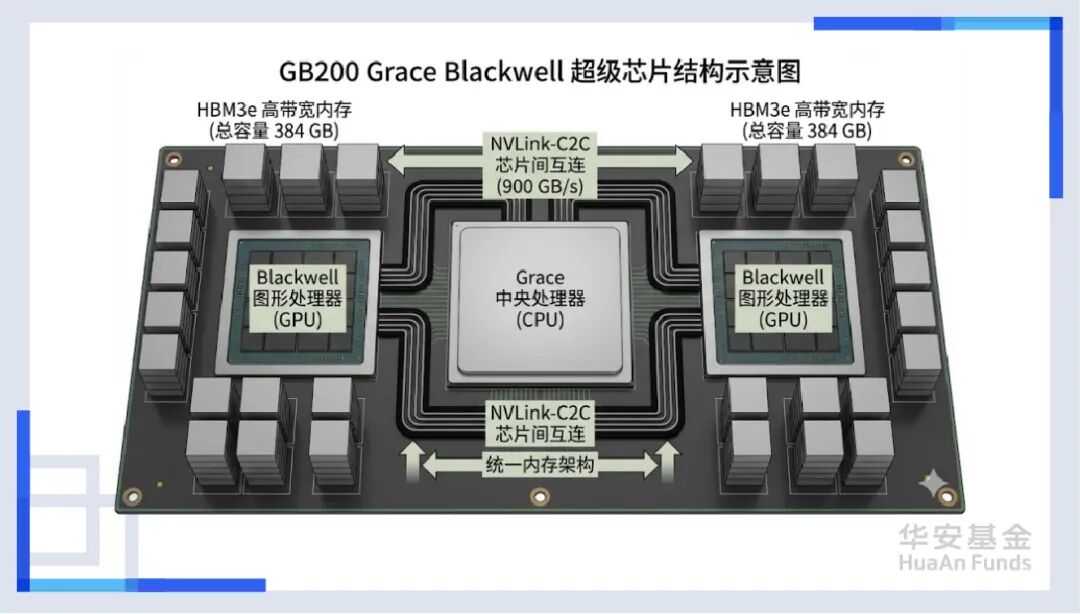
如果我告诉你,决定这场人工智能革命未来的,可能根本不是那块万众瞩目的芯片呢? 如果我告诉你,那块芯片只是一辆法拉利的引擎,而为了让这台引擎转起来,我们需要造一辆车、修一条路、甚至建一座城呢?而这座城,叫做AI数据中心(AI Data Center)。
在过去20年,芯片的速度增长了6万倍,但负责搬运数据的带宽只增长了30倍。这就像我们造出了光速飞船,却只能在泥泞的土路上推着前行。
而今天,我们不仅要推开那扇沉重的AI数据中心大门,更要拿一把手术刀,把这个庞大的算力巨兽解剖开来。我们将从微观的原子封装讲起,穿过光子与电子的高速公路,潜入沸腾的液冷池,最后抵达那个足以吞噬城市电网的能源心脏。
大家坐稳扶好,算力的列车即将开跑。

大脑再造——存储、封装与测试
我们的旅程,从一颗芯片的内部构造开始。 在很长一段时间里,我们只在乎GPU算得快不快。这就像我们只关心工厂里的工人干活麻不麻利。但是,当Genimi、ChatGPT这种参数量达到万亿级别的大模型出现后,第一堵墙出现了——存储墙(Memory Wall)。
想象一下,GPU是一个每秒能拧一万个螺丝的超级工人(算力强),但他旁边的零件仓库(内存)离他非常远,而且门太小。工人大部分时间不是在干活,而是在等零件,这就是传统架构的死穴。
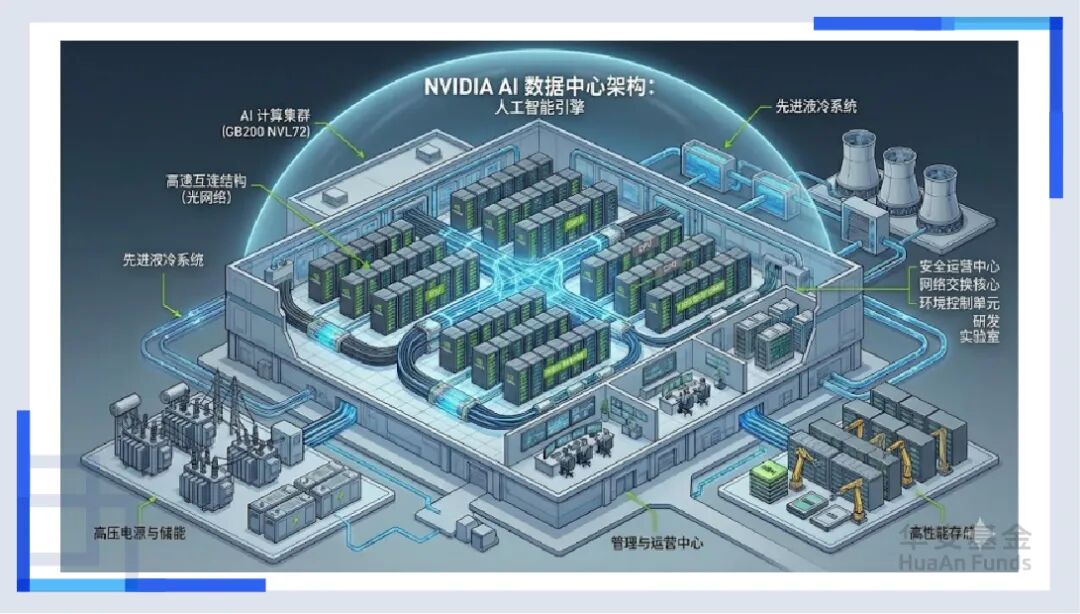
为了拆掉这堵墙,一种叫HBM(高带宽存储器)的技术诞生了。 如果说传统内存是把仓库建在郊区,那HBM就是直接把仓库搬到了工人的手边,并且是盖成了摩天大楼。通过TSV(硅通孔)技术,我们在指甲盖大小的地方打通了数千条垂直的高速通道。现在,数据不再是涓涓细流,而是像瀑布一样直接灌入GPU。没有HBM,目前所有的AI大模型都会因为“缺粮”而饿死。
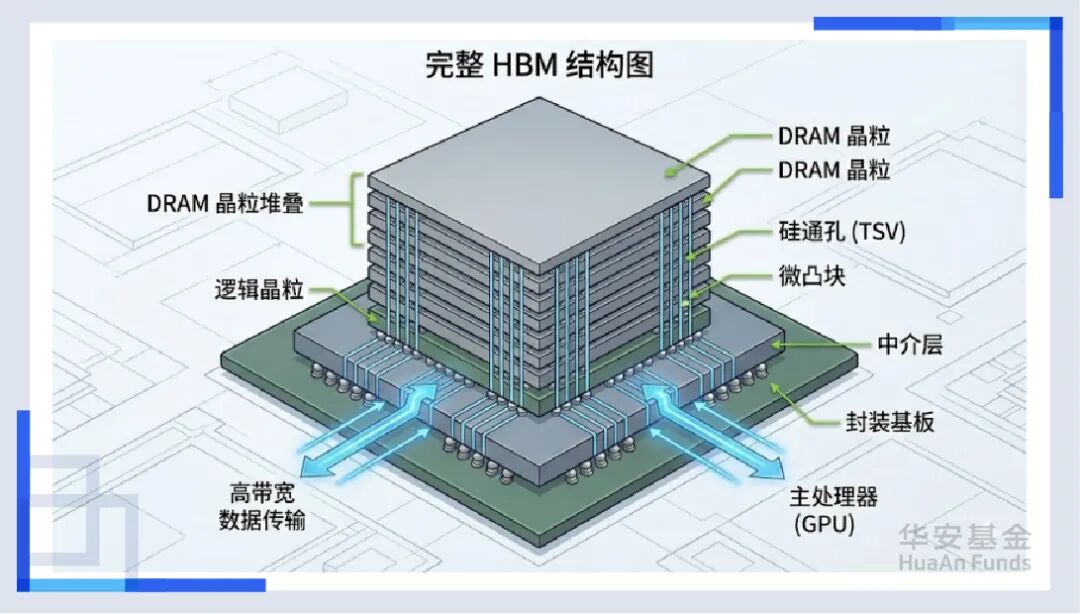
但是,问题来了。怎么把这个超级工人(GPU)和这几栋摩天大楼(HBM)紧紧地捆在一起,让它们像一个整体一样工作?这就引出了产业链的第一个“隐形王者”——先进封装(CoWoS)。
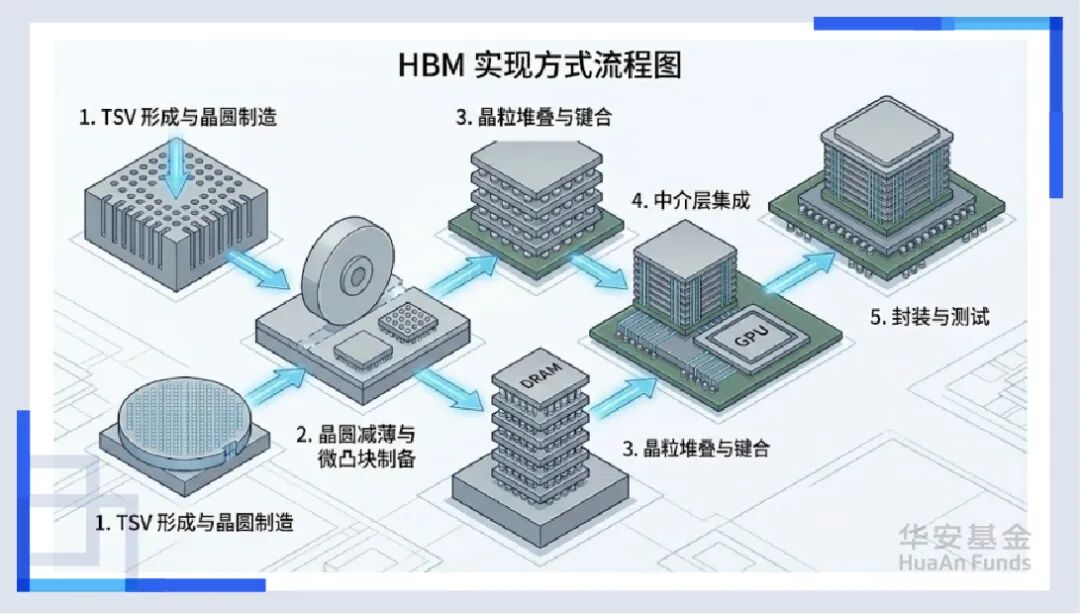
这不再是简单的“包装”,这是在微米尺度上的“搭积木”。台积电的CoWoS产能之所以比GPU本身还抢手,就是因为只有通过这种技术,才能把这些不同的芯片“缝合”成一个超级大脑,这也直接带动了后道测试设备的爆发。因为芯片结构太复杂了,每一个焊点都不能出错。以前的测试是走过场,现在的测试是“ICU体检”,这也让测试机的价值量成倍增长。
神经重构——PCB、铜缆与光通信
搞定了芯片内部的“内循环”,数据终于冲出了芯片。现在,它要面对的是如何在服务器内部,以及服务器之间进行长途奔袭。就像神经元中的电信号传导一样,这里正在上演一场光子、铜缆与PCB的“三国杀”。
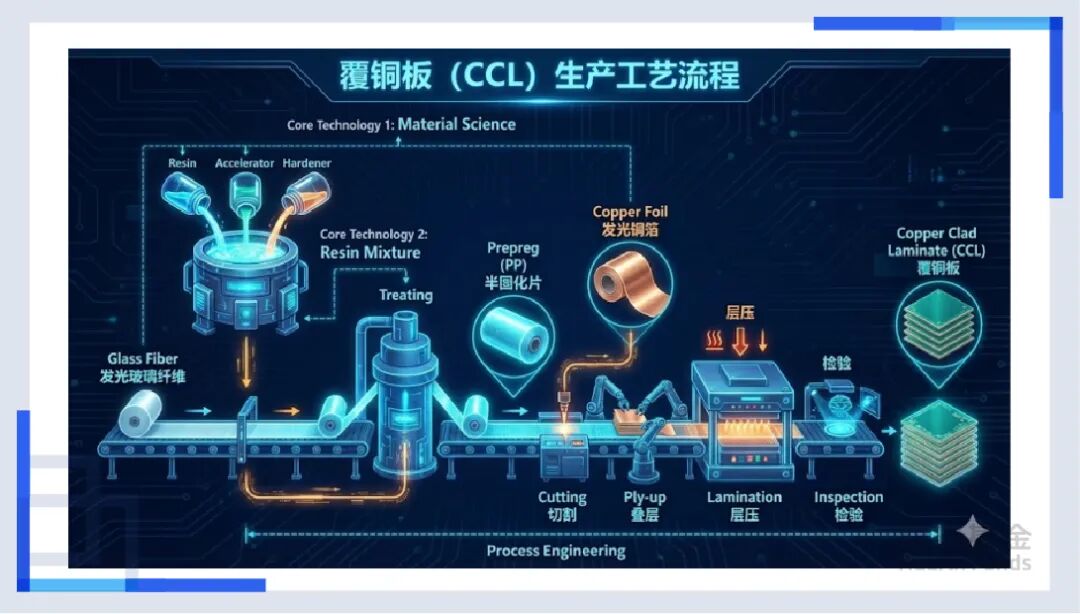
首先是地基——PCB(印制电路板)。在很多人的印象里,PCB不就是一块绿色的板子吗,几十块钱一张?错。在AI服务器里,PCB是精密的高速公路系统。为了承载112G甚至224G的高速信号,AI服务器的PCB层数从普通的8层增加到了20层甚至30层。而且,用的材料不再是普通的环氧树脂,而是极其昂贵的M9等级低损耗材料。特别是英伟达的GB200,因为它太精密了,甚至开始引入HDI(高密度互连)技术。这就像是在一块指甲盖大小的地方,要把立交桥修到100层高,而且不能有任何塌陷。就这样,单台服务器的PCB价值量翻了数倍。
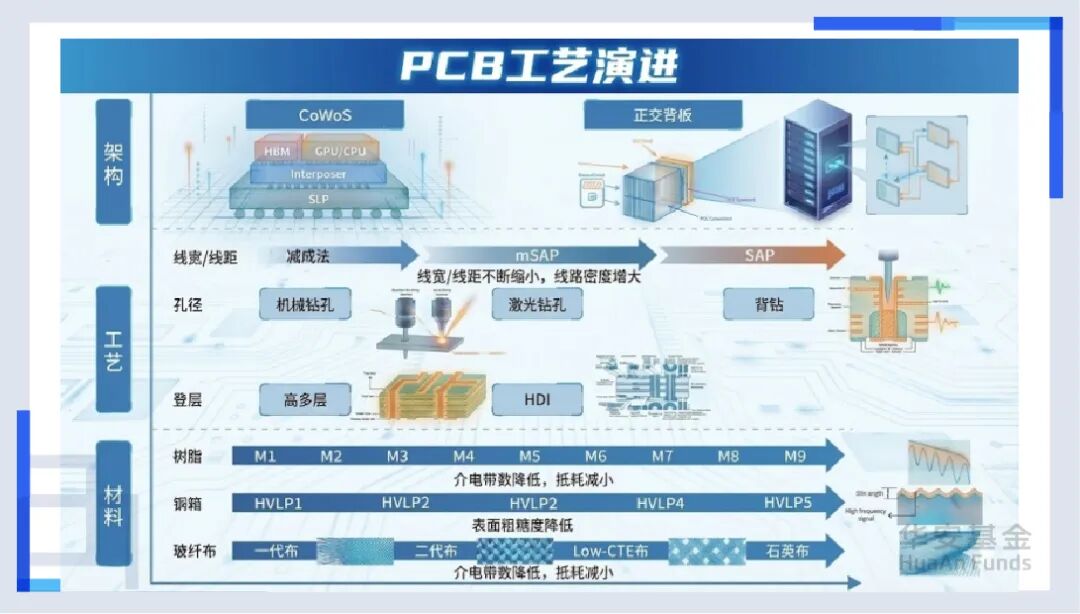
紧接着,一个反直觉的现象出现了——“铜”的回归。在英伟达最新的GB200机柜里,出现了大量粗壮的铜缆和覆铜板(CCL)。你可能听说过“光进铜退”,也就是光纤比铜要好,那为什么最先进的AI机柜里要用铜?因为在机柜内部,一米以下的铜缆比光纤更便宜、更可靠、功耗更低。毕竟,NVLink铜互连是实现“超节点”(72卡集群)的关键,这也是铜等有色金属不断创下新高的一个逻辑。

但是,一旦出了机柜,超过了几米远,铜线就废了,信号也会衰减成一团乱码。这时候,必须请出今年以来的绝对主角——光通信。
在传统的可插拔光模块里,有一个关键部件叫DSP(数字信号处理芯片),它就像是一个“翻译官”兼“整形医生”,当电信号经过长途跋涉变得歪瓜裂枣、充满噪声时,DSP负责把信号整形、放大、清理干净,然后再交给激光器发射出去。
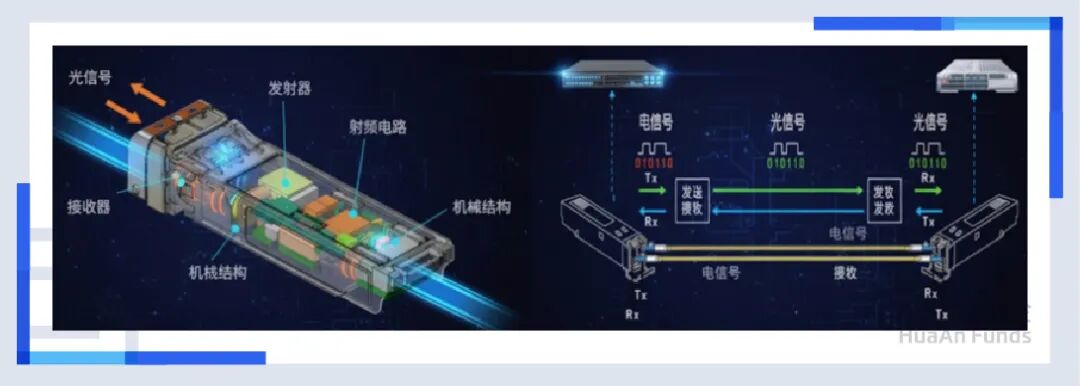
但这样的代价是昂贵的。在高速光模块中,这颗只有指甲盖大小的DSP芯片,竟然消耗了整个模块50%的电量!在400G时代,我们还能忍受这个“税收大户”。 但到了800G和1.6T时代,DSP产生的热量和功耗,已经成了整个数据中心的无法承受之重。
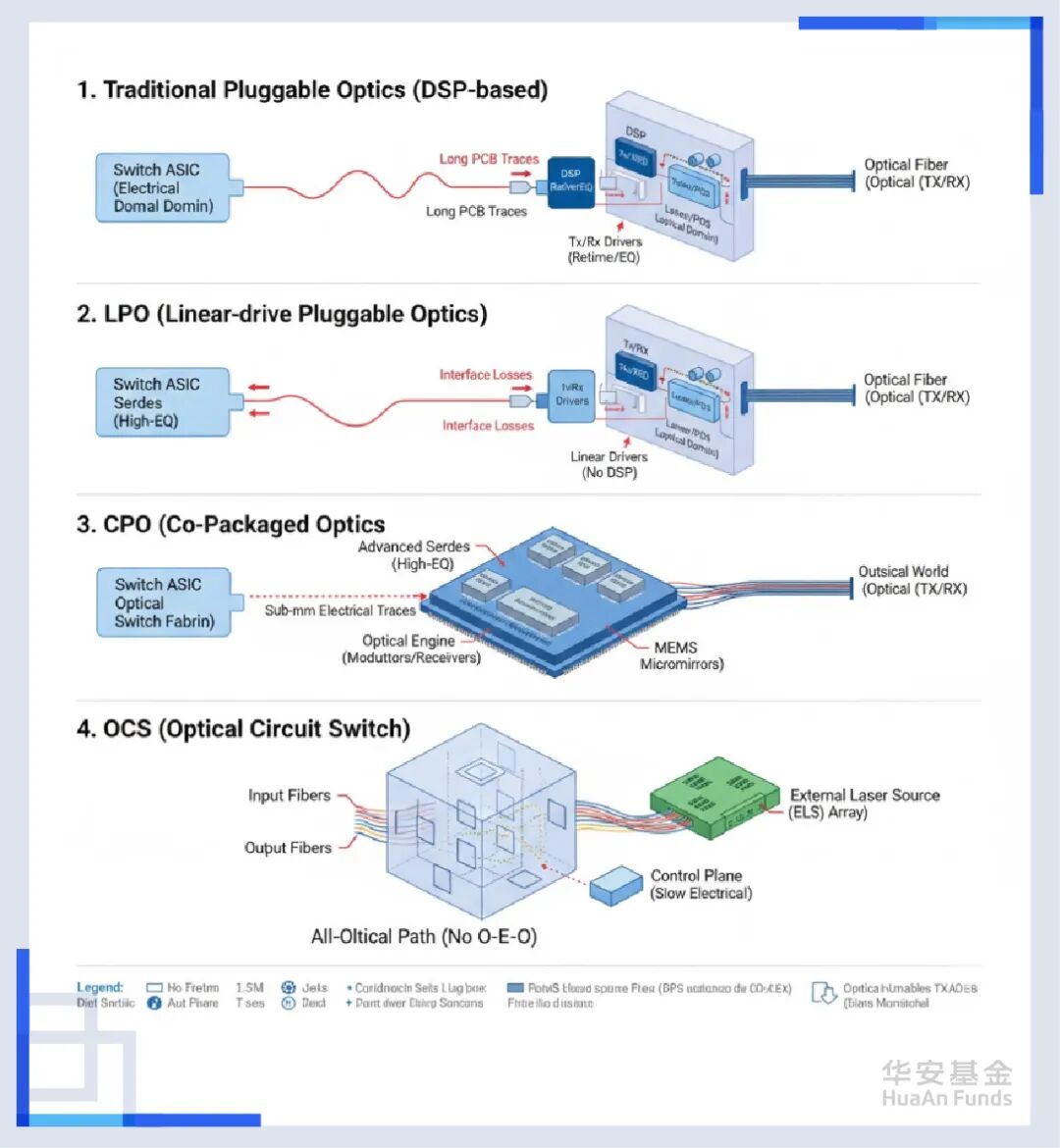
所以在这时候,CPO(光电共封装)登场了。当信号穿越PCB铜线的层层阻碍等待DSP救援时,CPO说我直接不救了,直接搬家,把光引擎(Optical Engine)直接封装在GPU的同一个基板上,距离直接干到几毫米,信号不就来不及衰减了。如果这样做,还要DSP干什么?还要昂贵的PCB板材干什么?这也意味着,在CPO模式下,光模块变成了芯片的一部分。
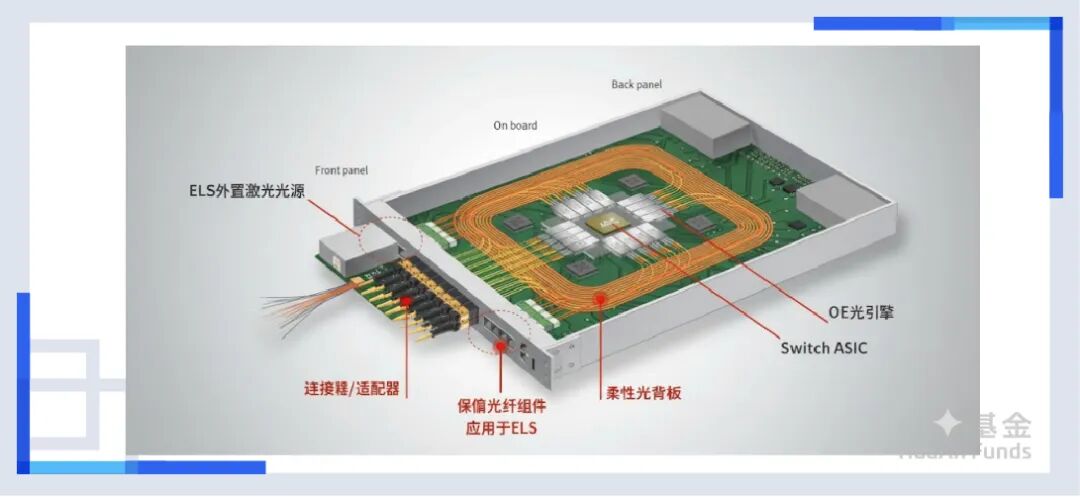
当然,除了CPO,还有直接把DSP芯片砍掉的LPO(线性驱动可插拔光模块),以及谷歌押注的,直接消灭电交换,实行全光交换的OCS(光路交换)。
皮肤汗腺——风冷与液冷
当数万个GPU全速运转,当光子与电子在高速公路上狂飙,物理学尤其是热力学最无情的一面露出了獠牙——热量。
热量,是算力最大的敌人。 高温会导致电子迁移,导致芯片降频,甚至直接烧毁。在传统的机房里,我们用风扇狂扇风,用空调吹冷风。但在AI时代,风冷已经没用了。当单机柜功率密度突破了100kW,对着它吹风,就像是用嘴去吹灭喷发的火山。
所以,在AI时代,唯一的出路是——液冷。 把芯片“泡”在液体里(浸没式),或者让液体流过芯片表面的冷板(冷板式)。就像皮肤的汗腺,把体内的热量源源不断从表皮散发,防止我们中暑。这不仅是散热方式的改变,更是数据中心形态的革命。

这不仅仅是卖风扇、卖空调还是卖水管的问题,这关乎到整个系统的可靠性。 你想想看,在价值几百万美元的电子设备里通水管,这需要多大的勇气? 任何一滴泄漏都是灾难。 所以,液冷技术的壁垒,比你想象的要高得多。快接头、分液单元(CDU)、冷却液的配方,每一个环节都是高科技。
心脏动脉——电源与储能
解决了热量,我们终于迎来了那个最底层、最朴实,但也最致命的瓶颈——电能。 马斯克曾经说过:“缺芯之后,就是缺电。”而AI数据中心,就是一只永远吃不饱的“电老虎”。 但这不仅仅是电量够不够的问题,更是“电能质量”好不好的问题。
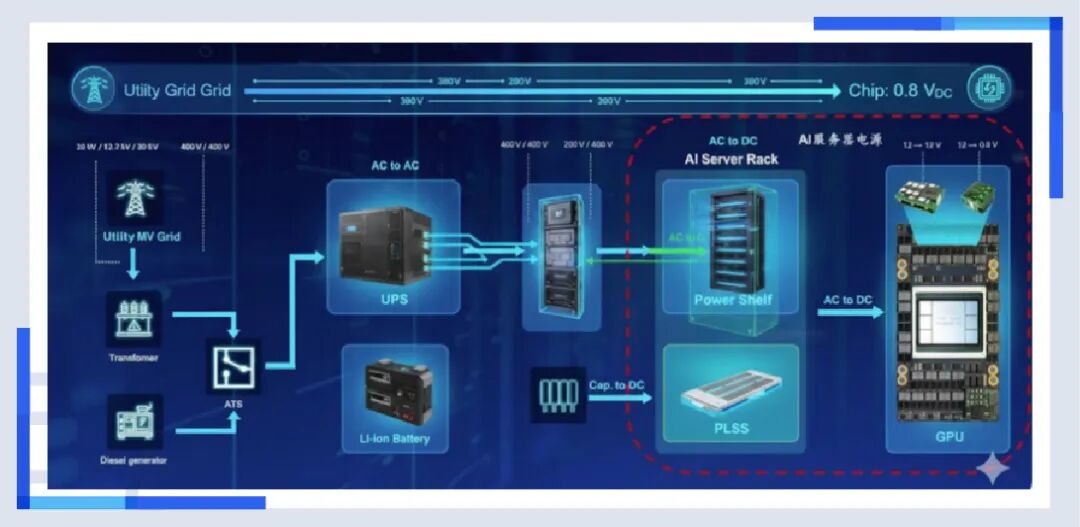
当大模型开始训练的一瞬间,数万张显卡同时满载,功耗会在毫秒级的时间里瞬间飙升。这种恐怖的电流脉冲(Spike),足以击穿普通的供电系统。如果电源扛不住这一波冲击,服务器就会宕机,几百万美元的训练进度瞬间归零。
这就是为什么服务器电源突然变得这么贵。这不是普通的电源,这是高精密、高功率密度的能量管理系统。我们需要钛金级的转换效率,需要更快的响应速度。从UPS(不间断电源)到HVDC(高压直流),供电架构也在发生剧变。

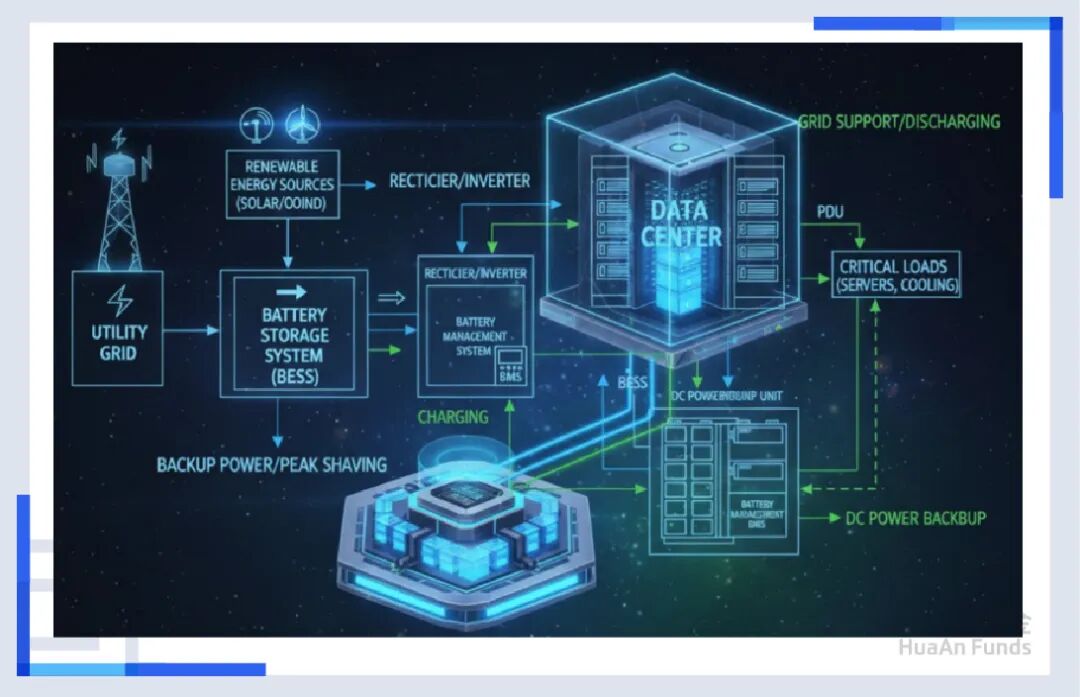
为了伺候这只巨兽,数据中心甚至开始自建电厂,储能系统也成为了标配。 它不仅是停电时的备用,更是为了削峰填谷,平滑那些可怕的电流尖峰。从某种意义上说,算力竞争的尽头,是能源竞争。谁能搞到便宜、稳定、绿色的电,谁才能把大模型跑下去。可控核聚变,就是未来全地球村的希望。
全身整合——组装
当你把芯片、存储、光模块、PCB、电源、散热器都准备好了,谁把它们变成一台机器?当然是组装(ODM)。很多人看不起组装,觉得这是拧螺丝的活。如果你还这么想,那你对AI服务器一无所知。
以英伟达的GB200 NVL72为例,这不仅仅是一台服务器,它更是一个精密仪器。 想想看,在一个机柜里,塞进72个高热芯片,布满几千根铜缆和光纤,通上几千瓦的高压电,还要通水冷却。最重要的是,为了提高效率,服务器需要采用了Blind Mate(盲插)技术,几百个接口必须一次性对准,精度要求在毫米维度。

在这个过程中,只要有一根线接虚了,有一个螺丝没拧紧导致散热不均,整个系统就会瘫痪。所以,组装不仅是拧螺丝,更是系统集成能力的集中体现:你需要懂热力学,懂流体力学,懂电磁兼容,甚至要懂量子力学,还要有极强的供应链管理能力。
所以,你认同吗——供应链的交付能力,本身就是算力的一部分。在这个环节,中国制造的效率和工艺,依然是全球最强的护城河。
算力是泡沫吗?
讲到这里,我相信屏幕前的很多同学都想问一个问题: 你吹了半天技术,背后的资本开支也在无底洞似的投入,相关公司的股价更是已经涨上天了,那算力以及背后的整个AI产业会不会又是一次互联网泡沫?
这是当前市场上最大的分歧,也让我想起来过去两年大火的“元宇宙”。当Facebook把名字改成了Meta,宣称我们要移民到数字世界时;当资本疯狂涌入,在那个粗糙的虚拟世界里炒地皮、开画展时,基建搭好了,路修好了,却没有人来。因为那个世界是荒芜的,用户没有在那里面找到不可替代的价值。

但这一次,AI的逻辑,和元宇宙截然相反。
毕竟,元宇宙是“建好了空城等人来”,而AI是“城门刚开,就被挤爆了”。这不是资本和供给侧在强推,而是真实的需求在倒逼供给。当一个程序员发现AI能帮他少写50%的代码,当一个画师发现AI能帮他省掉3天的草图时间,这种生产力的释放让算力根本就不够用。就像这篇文章的所有图片我都是用AI生成的一样,大模型带来的效率提升的确不可估量。
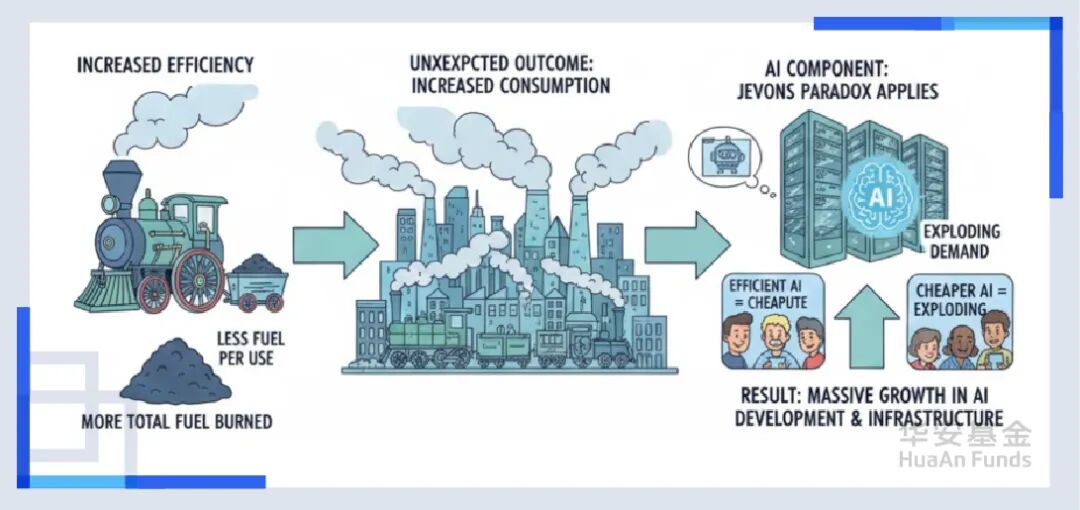
这也让我想起了年初大家热议的“杰文斯悖论(Jevons Paradox)”。当时DeepSeek横空出世,把百万Token的成本打到几毛钱时,华尔街恐慌,算力回调,市场担心如果模型越来越快、越来越便宜,那我们还需要那么多昂贵的GPU吗?还需要那么多光模块吗?硬件需求是不是就真要见顶了?
但反过来想,当算力的单位成本越来越低,被智能化的场景不就越来越多了,在这种情况下总算力的需求反而会指数级上升。毕竟DeepSeek看似是在搞价格战,实则是在把AI从奢侈品变成了日用品。一旦智能变成了水和电,你还会担心我们会因为“省水”而导致水厂倒闭吗? 不,我们会造出洗衣机、洗碗机、游泳池,去消耗更多的水。
所以,AI算力是不是泡沫我不知道,最起码在当下,只要你还看好AI,只要“智能”这个商品还有降本增效的空间,算力的天花板或许就还没有到来。
尾声
故事讲到最后,让我们把目光收回到AI数据中心这栋巨大的建筑本身。
在很长的一段时间里,我们把这里叫作“数据中心”。但这个名字其实已经过时了。在互联网时代,它是图书馆,是用来存数据的。但在AI时代,它的本质变了。
现在,这里是工厂,更是硅基文明的“数字熔炉”。
这座高炉的逻辑非常简单,但也极其残酷:输入端,是海量的电能和数据原料;输出端,是经过提炼的、昂贵的“智能Token”。

在这座“数字熔炉”里,光模块是它的神经传导,液冷是它的散热循环,电源是它的心脏泵血,GPU是它的反应核心。所有这些复杂的产业链,不管是CPO还是HBM,不管是铜缆还是PCB,最终都只服务于一个唯一的、极致的物理目标——提高“能量”转化为“智能”的效率。
因此,当你下次再看到那些关于光模块和CPO暴涨、关于存储爆发的新闻时,不要把它们看作是孤立的事件。它们是这座“数字熔炉”为了燃烧得更猛烈、更持久而进行的自我进化。尽管这种进化可能还不成熟,但依然寄托着人类对AGI的憧憬与希望。
所以,在这个时代,衡量一个国家、一家公司竞争力的终极刻度,或许不再是拥有多少石油或钢铁建筑,而是拥有多少座这样的高炉,以及——谁能用更少的电,烧出更多的智慧。
这轰鸣声,不是噪音,这是第四次工业革命的引擎声。